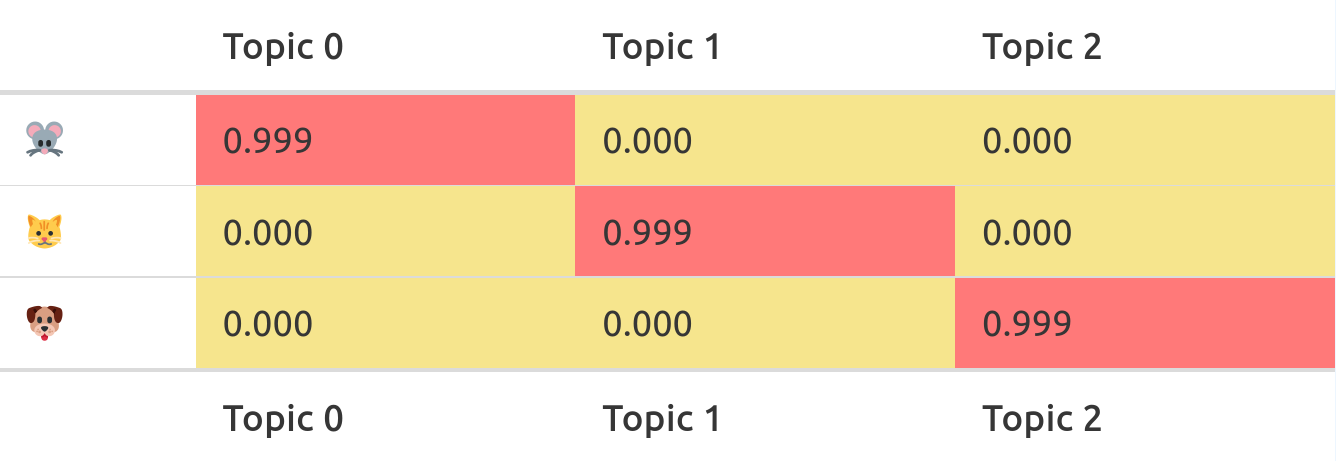
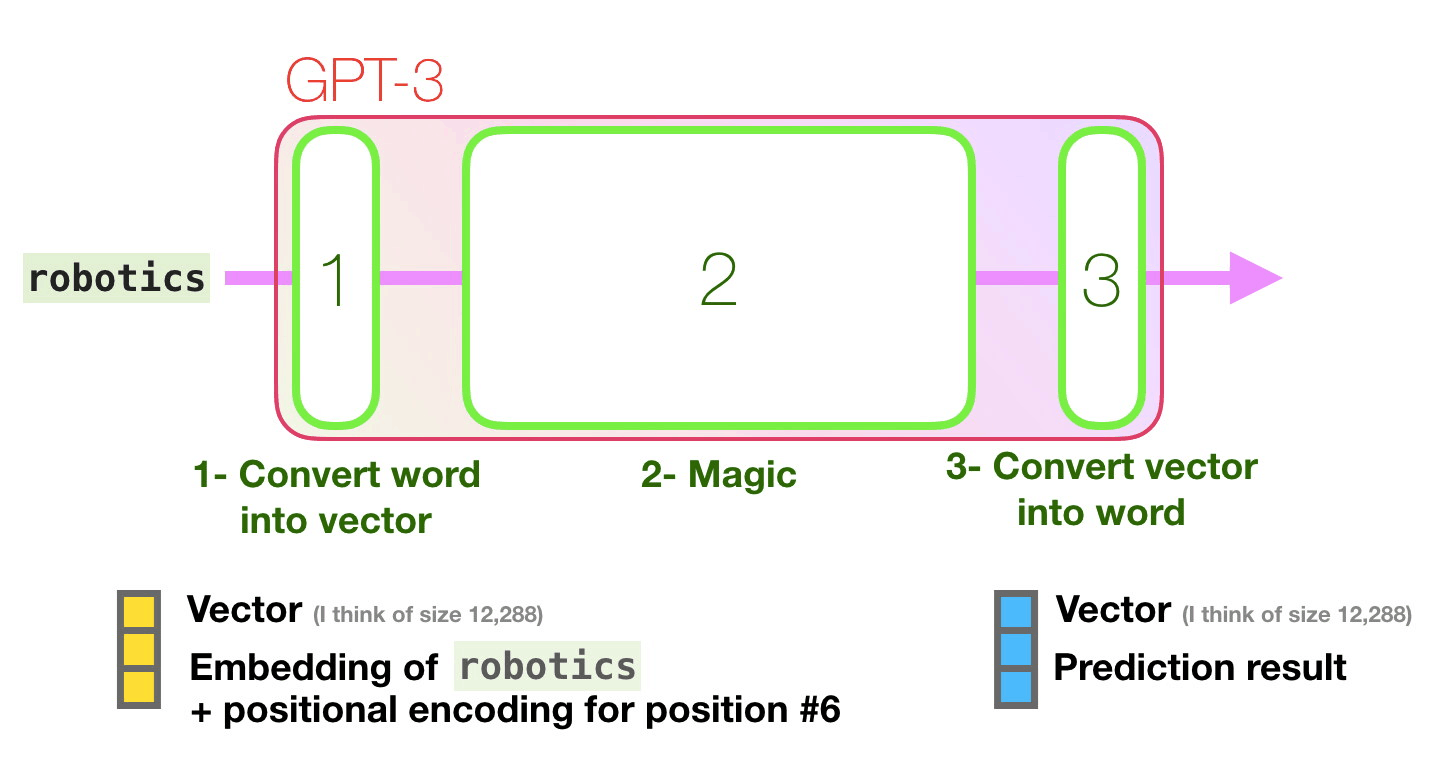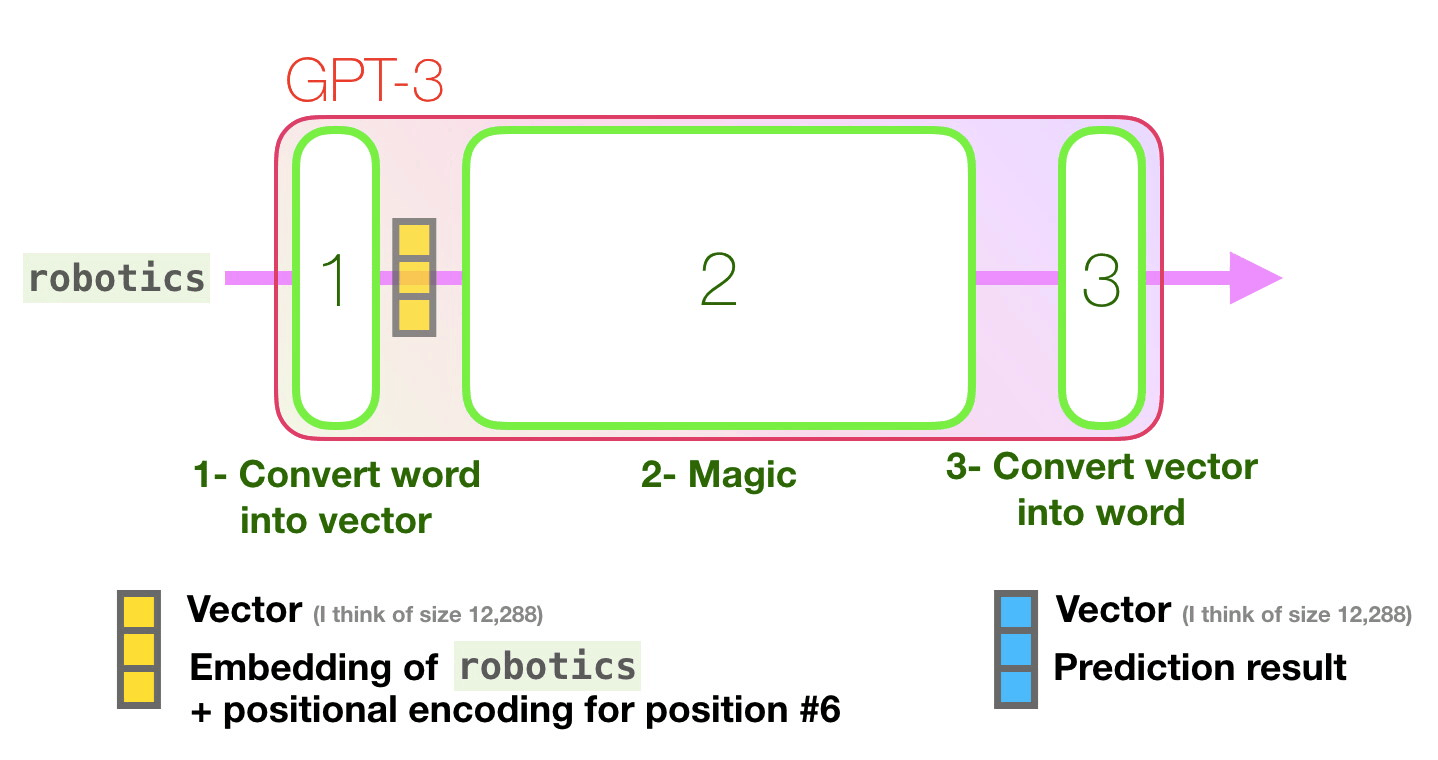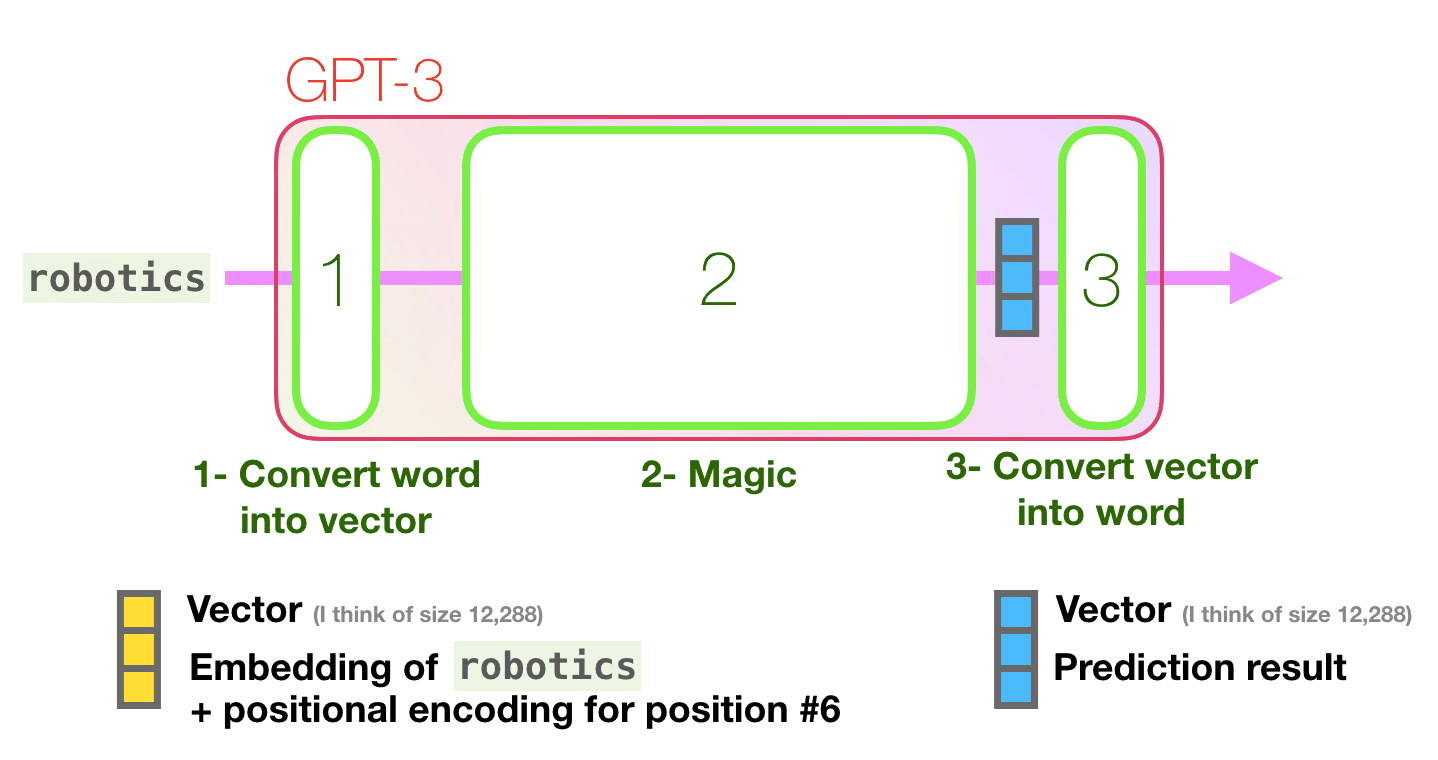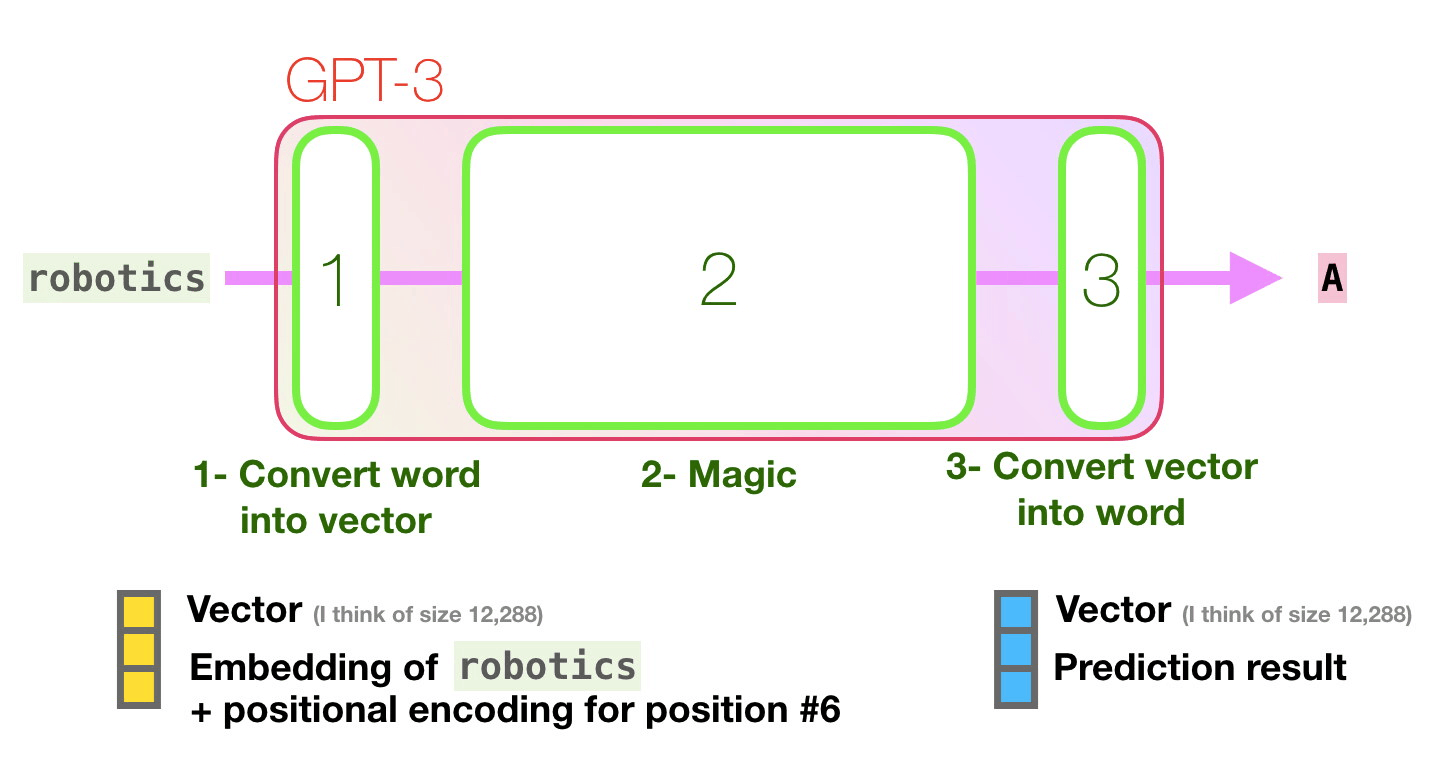
Computers don’t read text, they only can deal with numbers
For this reason, so far, we tokenized our texts (e.g., in words) and summarized their frequency across texts to create a document-feature matrix within the bag-of-words model
Such a text representation has some issues:
Treats words as equally important (→ requires removal of noise, stopwords…)
Ignores word order and context
Results in a sparse matrix (→ computationally expensive)
As mentioned before, we can compute similarity scores for word pairs:
nearest_neighbors <-function(tbl, word, n =15) { comp <-filter(tbl, term == word)if (nrow(comp) <1L) stop("word ", word, " not found in the embedding") sim <- proxyC::simil(as.matrix(select(comp, -term)), as.matrix(select(tbl, -term)), method ="cosine") # calculate cosine similarity# get the n highest values plus original word rank <-order(as.numeric(sim), decreasing =TRUE)[seq_len(n +1)] tibble(word = word,neighbor = tbl$term[rank],similarity = sim[1, rank] )}
But we can also generalize word embeddings to entire sentences (or even texts):
library(rollama)# Example sentencesmovies <-tibble(sentences =c("This movie is great, I loved it.", "The film was fantastic, a real treat!","I did not like this movie, it was not great.","Today, I went to the cinema and watched a movie","I had pizza for lunch."))# Get embeddings from a sentence transformermovie_embeddings <-embed_text(movies$sentences, model ="nomic-embed-text")# Each text has now 768 valuesmovie_embeddings
The subtle similarity of some texts in the example
We can see that text 2 is most similar to text 1: Both express a very similar sentiment, just with different words (“great” ≈ “fantastic”; “I loved it” ≈ “A real treat”)
Text 2 is still similar to text 3 (after all it is about movies), but less so compared to text 1 (“fantastic” is the opposite of “not great”)
Text 4 still shares similarities (the context is the cinema/watching movies), but text 5 is very different as it doesn’t contain similar words and is not about similar things (except “I”).
sentences movie1 movie2 movie3 movie4 movie51 This movie is great, I loved it. 1.0000000 0.7679983 0.7046627 0.6746315 0.47579852 The film was fantastic, a real treat! 0.7679983 1.0000000 0.6022398 0.6897439 0.49435113 I did not like this movie, it was not great. 0.7046627 0.6022398 1.0000000 0.6220552 0.48018144 Today, I went to the cinema and watched a movie 0.6746315 0.6897439 0.6220552 1.0000000 0.57867635 I had pizza for lunch. 0.4757985 0.4943511 0.4801814 0.5786763 1.0000000
From Sparse to Dense Matrix Representation
Using embedding vectors instead of word frequencies further has the advantages of strongly reducing the dimensionality of the DTM: instead of (tens of) thousands of columns for each unique word we only need hundreds of columns for the embedding vectors (→ dense instead of sparse)
This means that further processing can be more efficient as fewer parameters need to be fit, or conversely that more complicated models can be used without blowing up the parameter space.
What are transformers?
Until 2017, the state-of-the-art for natural language processing was using a deep neural network (e.g., recurrent neural networks, long short-term memory and gated recurrent neural networks)
In a preprint called “Attention is all you need” (Vaswani et al. 2017), published in 2017 and cited more than 95,000 times, the team of Google Brain introduced the so-called Transformer, a a neural network-type architecture that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Transformer models apply an evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways even distant data elements in a series influence and depend on each other.
Self-Attention
In general terms, self-attention works encodes how similar each word is to all the words in the sentence, including itself.
Once the similarities are calculated, they are used to determine how the transformers encodes each word.
Self-Attention
In general terms, self-attention works encodes how similar each word is to all the words in the sentence, including itself.
Once the similarities are calculated, they are used to determine how the transformers encodes each word.
Self-Attention
In general terms, self-attention works encodes how similar each word is to all the words in the sentence, including itself.
Once the similarities are calculated, they are used to determine how the transformers encodes each word.
Self-Attention
In general terms, self-attention works encodes how similar each word is to all the words in the sentence, including itself.
Once the similarities are calculated, they are used to determine how the transformers encodes each word.
So why are transformer models important?
Transformer models apply an evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways even distant data elements in a series influence and depend on each other.
this actually simplifies learning:
No need for recurrent or convolutional network structures
Based solely on attention mechanism (stacked on top of one another)
Required less training time (can be parallelized)
It thereby outperformed prior state-of-the-art models in a variety of tasks
The transformer architecture is the back-bone of all current large language models and so far drives the entire “AI revolution”
Large language models are language models that are large
Like the “big” in “big” data, the term is relative to what is considered at the time
It refers to the training data, the parameter size, and the computational resources needed for training
As models get larger, they approach what appears like general-purpose language understanding
Current generations of LLMs are still just a type of artificial neural networks (mainly transformers!) and are (pre-)trained using self-supervised learning and semi-supervised learning
What are generative large language models
trained to predict/generate next word in a conversation
surprisingly good at emulating humans to complete tasks
can be controlled with natural language
have become very popular through ChatGPT (a browser interface to communicate with OpenAI’s GPT models)
library(askgpt)options(askgpt_chat_model ="gpt-4")askgpt("What are generative Large Language Models?")#> ── Answer ────────────────────────────────────────────────────────#> Generative Large Language Models are artificial#> intelligence models that generate human-like text.#> They are designed to understand and predict human #> language patterns. GPT-3 by OpenAI is a good #> example of a Generative Large Language Model. #> They can generate stories, poems, or even technical#> content.#>#> These models are 'generative' because they create #> (or generate) new content. They are 'large' because#> they are trained on large amounts of data, and the #> term 'language model' is due to their ability to #> use and understand human language. They learn to #> produce text by being fed huge amounts of existing #> text data, learning patterns and context from that #> data, and using this understanding to create new, #> relevant text that follows the rules of the #> language it was trained on.
Running model locally through Ollama
library(rollama)query("What are generative Large Language Models?", model ="llama3:8b")#> ── Answer from llama3:8b───────────────────────────────────────────#> #> Generative large language models (LLMs) are a type#> of artificial intelligence (AI) model that is#> capable of generating new, > original text or#> language based on patterns and structures learned#> from large datasets. These models have become#> increasingly popular in recent years due to their#> ability to generate human-like text, respond to#> questions, and even create entire stories.#> #> Here's how they work: #> #> 1. **Training**: Generative LLMs are trained on #> massive amounts of text data, which can be sourced#> from various places like books, articles, social#> media, or online forums. #> 2. **Language patterns**: The models analyze the training data to identify patterns,#> relationships, and structures in language. This#> helps them learn how to generate new text that is#> coherent, natural-sounding, and meaningful.#> 3. **Generator**: The trained model has a generator#> component that produces new text based on the#> learned patterns. This can be done by sampling#> from probability distributions or using techniques#> like autoregressive models.#> 4. **Conditioning**: To control the output of the #> model, conditioning mechanisms are used to specify#> what kind of text should be generated. For example,#> you might provide a prompt or topic for the model#> to generate text about. #> #> Some key characteristics of generative LLMs include:#> #> 1. **Autoregressive**: Generative models predict #> the next token in a sequence (e.g., word) based on #> the previous tokens.#> 2. **Probabilistic**: The models assign #> probabilities to each possible output, allowing #> them to generate diverse and creative text.#> 3. **Adversarial training**: Some models are trained#> using adversarial examples, which helps them learn#> to generate text that is more realistic and#> challenging for humans to distinguish from#> human-written text. #> #> Applications of generative LLMs:#> #> 1. **Text generation**: These models can#> be used to generate text for various purposes, such#> as chatbots, customer service > responses, or#> content marketing. #> 2. **Language translation**:#> Generative LLMs can be fine-tuned for language#> translation tasks, allowing them to translate text#> from one language to another.#> 3. **Content#> creation**: They can help generate new ideas,#> stories, or scripts by providing a starting point#> and then > continuing the narrative.#> 4. **Summarization**: Generative models can summarize#> long pieces of text into shorter summaries while#> preserving the original meaning.#> #> Some popular examples of generative LLMs include: #> #> 1. **OpenAI's GPT-3**: A highly advanced language #> model capable of generating human-like text and #> responding to questions. #> 2. **Google's BERT**: A transformer-based model #> that has achieved state-of-the-art results in #> various natural language processing (NLP) tasks, #> including sentiment analysis and question answering.#> #> These models have the potential to revolutionize #> many areas, from customer service and content #> creation to creative writing and > education.#> However, they also require careful consideration #> of their ethical implications and limitations.
Classification–Strategies
Prompting strategies
Prompting Strategy
Example Structure
Zero-shot
{"role": "system", "content": "Text of System Prompt"}, {"role": "user", "content": "(Text to classify) + classification question"}
One-shot
{"role": "system", "content": "Text of System Prompt"}, {"role": "user", "content": "(Example text) + classification question"}, {"role": "assistant", "content": "Example classification"}, {"role": "user", "content": "(Text to classify) + classification question"}
q <-tribble(~role, ~content,"system", "You assign texts into categories. Answer with just the correct category.","user", "text: the pizza tastes terrible\ncategories: positive, neutral, negative")query(q)
Classification–One-shot
q <-tribble(~role, ~content,"system", "You assign texts into categories. Answer with just the correct category.","user", "text: the pizza tastes terrible\ncategories: positive, neutral, negative","assistant", "Category: Negative","user", "text: the service is great\ncategories: positive, neutral, negative")query(q)#> #> ── Answer ────────────────────────────────────────────────────────#> Category: Positive
Neat effect: change the output structure
q <-tribble(~role, ~content,"system", "You assign texts into categories. Answer with just the correct category.","user", "text: the pizza tastes terrible\ncategories: positive, neutral, negative","assistant", "{'Category':'Negative','Confidence':'100%','Important':'terrible'}","user", "text: the service is great\ncategories: positive, neutral, negative")answer <-query(q)#> #> ── Answer ────────────────────────────────────────────────────────#> {'Category':'Positive','Confidence':'100%','Important':'great'}
Classification–Few-shot
q <-tribble(~role, ~content,"system", "You assign texts into categories. Answer with just the correct category.","user", "text: the pizza tastes terrible\ncategories: positive, neutral, negative","assistant", "Category: Negative","user", "text: the service is great\ncategories: positive, neutral, negative","assistant", "Category: Positive","user", "text: I once came here with my wife\ncategories: positive, neutral, negative","assistant", "Category: Neutral","user", "text: I once ate pizza\ncategories: positive, neutral, negative")query(q)
Classification–Chain-of-Thought
q_thought <-tribble(~role, ~content,"system", "You assign texts into categories. ","user", "text: the pizza tastes terrible\nWhat sentiment (positive, neutral, or negative) would you assign? Provide some thoughts.")output_thought <-query(q_thought)
Now we can use these thoughts in classification
q <-tribble(~role, ~content,"system", "You assign texts into categories. ","user", "text: the pizza tastes terrible\nWhat sentiment (positive, neutral, or negative) would you assign? Provide some thoughts.","assistant", pluck(output_thought, "message", "content"),"user", "Now answer with just the correct category (positive, neutral, or negative)")query(q)
Example: Sentiment Analysis
gLLMs often perform better on standard text classification problems
Let’s put this to a test with data from Atteveldt, Velden, and and (2021)
What do they do? Compare trained human annotators, crowd-coding, dictionary approaches, and supervised machine learning algorithms (including deep learning) on Dutch sentiment
library(tidymodels)# split data into training an test set (for validation)set.seed(1)reviews_split <-initial_split(reviews_embeddings)reviews_train <-training(reviews_split)# set up the model we want to uselasso_spec <-logistic_reg(penalty =tune(), mixture =1) |>set_engine("glmnet")# we specify that we want to do some hyperparameter tuning and bootstrappingparam_grid <-grid_regular(penalty(), levels =50)reviews_boot <-bootstraps(reviews_train, times =10)# and we define the model. Here we use the embeddings to predict the ratingrec_spec <-recipe(label ~ ., data =select(reviews_train, -id))# bringing this together in a workflowwf_fh <-workflow() |>add_recipe(rec_spec) |>add_model(lasso_spec)# now we do the tuningset.seed(42)lasso_grid <-tune_grid( wf_fh,resamples = reviews_boot,grid = param_grid)# select the best modelwf_fh_final <- wf_fh |>finalize_workflow(parameters =select_best(lasso_grid, metric ="roc_auc"))# and train a new model + predict the classes for the test setfinal_res <-last_fit(wf_fh_final, reviews_split)# we extract these predictionsfinal_pred <- final_res |>collect_predictions()
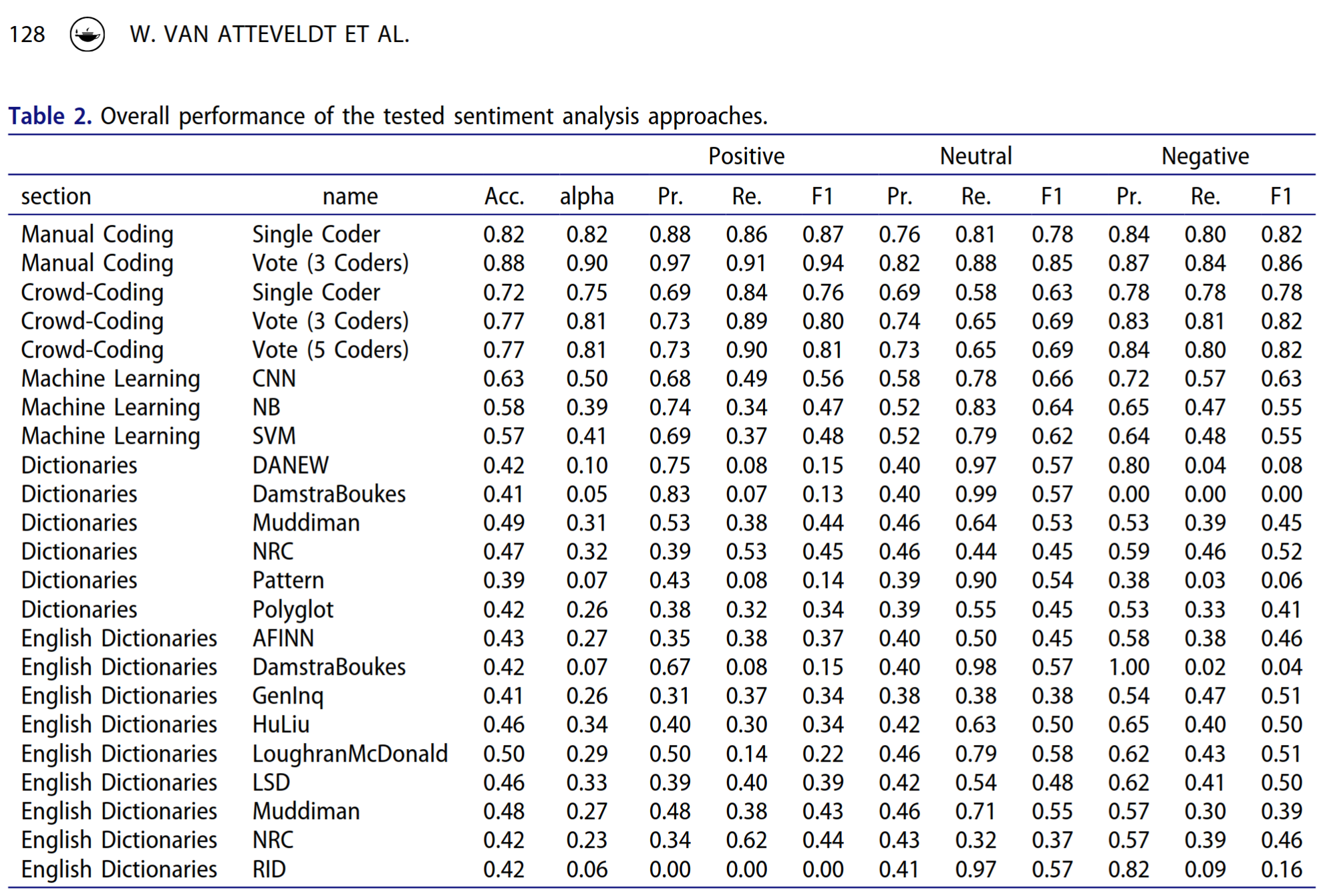
Check out results
library(gt)my_metrics <-metric_set(accuracy, kap, precision, recall, f_meas)my_metrics(final_pred, truth = label, estimate = .pred_class) |># I use gt to make the table look a bit nicer, but it's optionalgt() |>data_color(columns = .estimate,fn = scales::col_numeric(palette =c("red", "orange", "green"),domain =c(0, 1) ) )
.metric
.estimator
.estimate
accuracy
binary
0.9264800
kap
binary
0.8529560
precision
binary
0.9239043
recall
binary
0.9282258
f_meas
binary
0.9260600
Comparison to day-3: F1 = 0.72 and 0.71
Conclusion
Conclusion
LLMs bring many new possibilities for new research
A lot of it is untested and comes with risks
If you want to use models, think about: responsibility
Trust but verify!
References
Atteveldt, Wouter van, Mariken A. C. G. van der Velden, and Mark Boukes and. 2021. “The Validity of Sentiment Analysis: Comparing Manual Annotation, Crowd-Coding, Dictionary Approaches, and Machine Learning Algorithms.”Communication Methods and Measures 15 (2): 121–40. https://doi.org/10.1080/19312458.2020.1869198.
Bender, Emily M., Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. “On the Dangers of StochasticParrots: CanLanguageModelsBeTooBig? 🦜.” In Proceedings of the 2021 ACMConference on Fairness, Accountability, and Transparency, 610–23. Virtual Event Canada: ACM. https://doi.org/10.1145/3442188.3445922.
Gilardi, Fabrizio, Meysam Alizadeh, and Maël Kubli. 2023. “ChatGPT Outperforms Crowd Workers for Text-Annotation Tasks.”Proceedings of the National Academy of Sciences 120 (30). https://doi.org/10.1073/pnas.2305016120.
Grimmer, J., and B. M. Stewart. 2013. “Text as Data: ThePromise and Pitfalls of AutomaticContentAnalysisMethods for PoliticalTexts.”Political Analysis 21 (3): 267–97. https://doi.org/10.1093/pan/mps028.
Heseltine, Michael, and Bernhard Clemm von Hohenberg. 2023. “Large Language Models as a Substitute for Human Experts in Annotating Political Text.” OSF. https://doi.org/10.31219/osf.io/cx752.
Hicks, Michael Townsen, James Humphries, and Joe Slater. 2024. “ChatGPT Is Bullshit.”Ethics and Information Technology 26 (2): 38. https://doi.org/10.1007/s10676-024-09775-5.
Törnberg, Petter. 2023. “ChatGPT-4 Outperforms Experts and Crowd Workers in Annotating Political Twitter Messages with Zero-Shot Learning.” arXiv. http://arxiv.org/abs/2304.06588.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention IsAllYouNeed.” arXiv. https://doi.org/10.48550/ARXIV.1706.03762.
Weber, Maximilian, and Merle Reichardt. 2023. “Evaluation Is All You Need. Prompting Generative Large Language Models for Annotation Tasks in the Social Sciences. A Primer Using Open Models.”https://arxiv.org/abs/2401.00284.
Zhong, Qihuang, Liang Ding, Juhua Liu, Bo Du, and Dacheng Tao. 2023. “Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-Tuned BERT.” arXiv. http://arxiv.org/abs/2302.10198.