<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
</head>
<body>
<h1>My Headline</h1>
<p class="author">Me</p>
<p>This is the body of the text.</p>
<p>Consider this data:</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
<tr>
<td>John</td>
<td>25</td>
</tr>
<tr>
<td>Mary</td>
<td>26</td>
</tr>
</table>
</body>
</html>Obtaining Data
Module 02 GESIS Fall Seminar “Introduction to Computational Social Science”
The Plan for Today
- Learn what Web Scraping is
- Get an understanding of the web
- Learn how to identify patterns you can use for scraping
- Get an overview of relevant tools
- Learn about legal and ethical concerns (and myths)
 Louis Hansel via unsplash.com
Louis Hansel via unsplash.com
What is Web Scraping
- Used when other means are unavailable
- Scrape the (unstructured) Data
- A web-scraper is a program (or robot) that:
- goes to a web page
- downloads its content
- extracts data from the content
- then saves the data to a file or a database
- Unfortunately no one-size-fits-all solution
- Lots of different techniques, tools, tricks
- Websites change (some more frequently than others)
- Some websites make it hard for you (by accident or on purpose!)

What is Web Scraping
- Used when other means are unavailable
- Scrape the (unstructured) Data
- A web-scraper is a program (or robot) that:
- goes to a web page
- downloads its content
- extracts data from the content
- then saves the data to a file or a database
- Unfortunately no one-size-fits-all solution
- Lots of different techniques, tools, tricks
- Websites change (some more frequently than others)
- Some websites make it hard for you (by accident or on purpose!)
What is Web Scraping
- Used when other means are unavailable
- Scrape the (unstructured) Data
- A web-scraper is a program (or robot) that:
- goes to a web page
- downloads its content
- extracts data from the content
- then saves the data to a file or a database
- Unfortunately no one-size-fits-all solution
- Lots of different techniques, tools, tricks
- Websites change (some more frequently than others)
- Some websites make it hard for you (by accident or on purpose!)

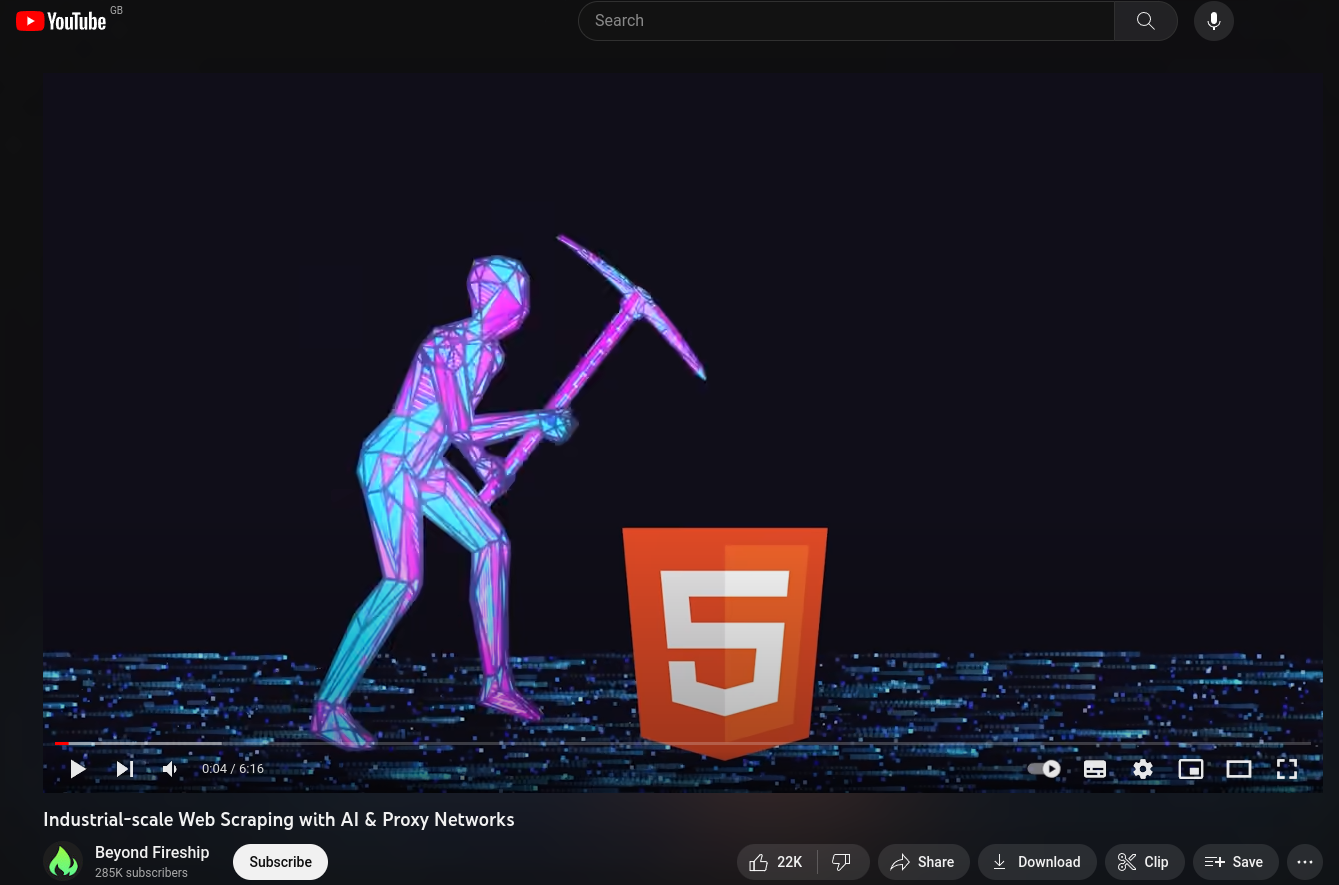
Web Scraping: A Three-Step Process
- Send an HTTP request to the webpage -> server responds to the request by returning (HTML) content
- Parse the HTML content -> extract the information you want from the nested structure of (HTML) code
- Wrangle the data into a useful format
Why Should You Learn Web Scraping?
- The internet is a data gold mine!
- Data were not created for research, but are often traces of what people are actually doing on the internet
- Reproducible and renewable data collection (e.g., rehydrate data that is copyrighted)
- Web Scraping let’s you automate data retrieval (as opposed to using tedious copy & past on some web site)
- It’s one of the most fun tasks to learn R and programming!
- It’s engaging and satisfying to find repeating patterns that you can employ to structure data (every website becomes a little puzzle)
- It touches on many important computational skills
- The return is good data to further your career (unlike sudokus or video games)

What is HTML
- HTML (HyperText Markup Language) is the standard markup language for documents designed to be displayed in a web browser
- Contains the raw data (text, URLs to pictures and videos) plus defines the layout and some of the styling of text

Image Source: Wikipedia.org
Example: Simple
Code:
<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
</head>
<body>
<p>This is the body of the text.</p>
</body>
</html>Browser View:
Example: With headline and author
Code:
<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
</head>
<body>
<h1>My Headline</h1>
<p class="author" href="https://www.johannesbgruber.eu/">Me</p>
<p>This is the body of the text.</p>
</body>
</html>Browser View:
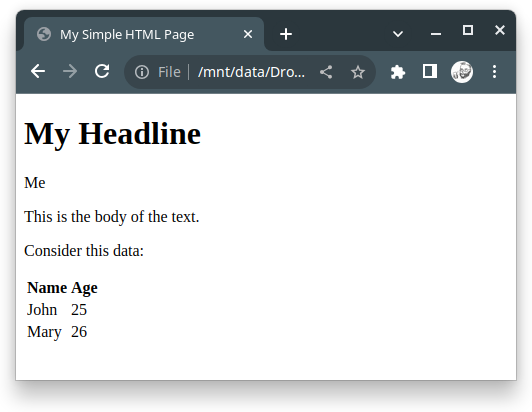
Example: With some data
Code:
Browser View:
Example: With an image
Code:
<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
</head>
<body>
<h1>My Headline</h1>
<p class="author">Me</p>
<p>This is the body of the text.</p>
<p>Consider this image:</p>
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/0/0c/About_The_Dog.jpg/640px-About_The_Dog.jpg" alt="About The Dog."></img>
</body>
</html>Browser View:
Example: With a link
Code:
<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
</head>
<body>
<h1>My Headline</h1>
<a href="https://www.johannesbgruber.eu/">
<p class="author">Me</p>
</a>
<p>This is the body of the text.</p>
</body>
</html>Browser View:
Example: CSS
HTML:
<!DOCTYPE html>
<html>
<head>
<title>My Simple HTML Page</title>
<link rel="stylesheet" type="text/css" href="example.css">
</head>
<body>
<h1 class="headline">My Headline</h1>
<p class="author">Me</p>
<div class="content">
<p>This is the body of the text.</p>
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/0/0c/About_The_Dog.jpg/640px-About_The_Dog.jpg" alt="About The Dog.">
<p>Consider this data:</p>
<table>
<tr class="top-row">
<th>Name</th>
<th>Age</th>
</tr>
<tr>
<td>John</td>
<td>25</td>
</tr>
<tr>
<td>Mary</td>
<td>26</td>
</tr>
</table>
</div>
</body>
</body>
</html>
CSS:
Browser View:
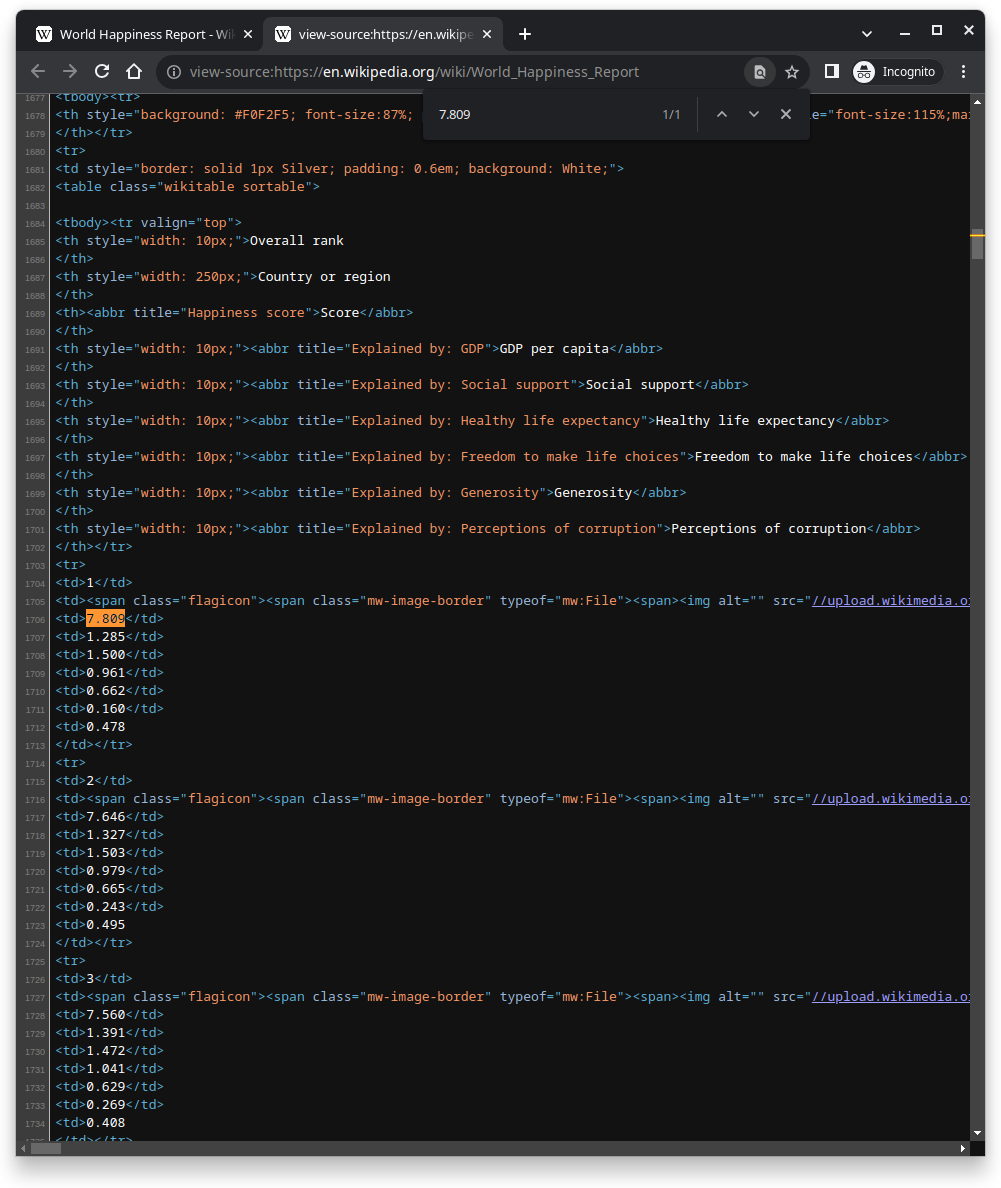
Example: World Happiness Report
Use your Browser to Scout


Use your Browser’s Inspect tool
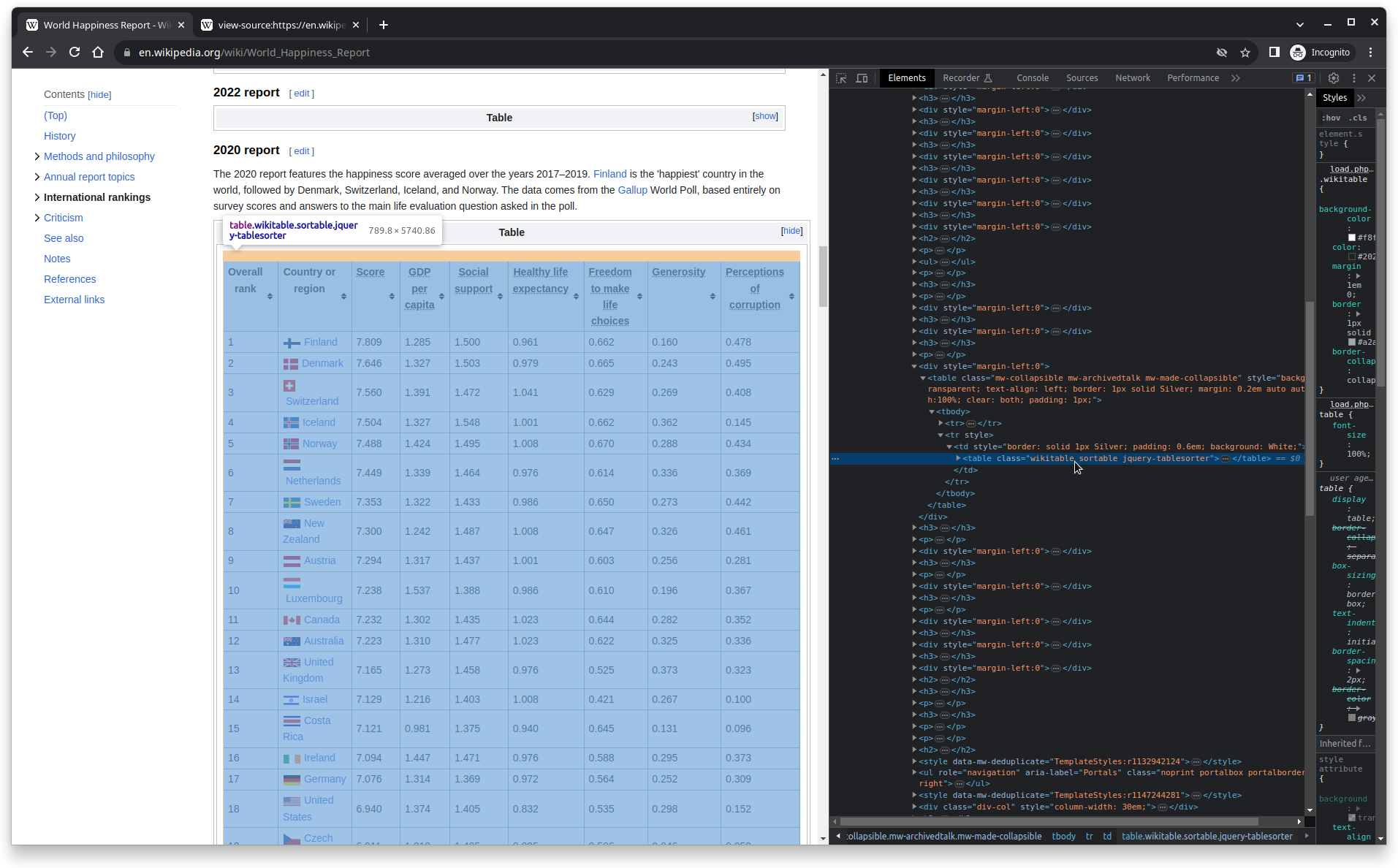
Note: Might not be available on all browsers; use Chromium-based or Firefox or enable in Safari.
Use rvest to scrape
library(rvest)
library(tidyverse)
# 1. Request & collect raw html
html <- read_html("https://en.wikipedia.org/w/index.php?title=World_Happiness_Report&oldid=1165407285")
# 2. Parse
happy_table <- html |>
html_elements(".wikitable") |> # select the right element
html_table() |> # special function for tables
pluck(3) # select the third table
# 3. No wrangling necessary
happy_table# A tibble: 153 × 9
`Overall rank` `Country or region` Score `GDP per capita` `Social support`
<int> <chr> <dbl> <dbl> <dbl>
1 1 Finland 7.81 1.28 1.5
2 2 Denmark 7.65 1.33 1.50
3 3 Switzerland 7.56 1.39 1.47
4 4 Iceland 7.50 1.33 1.55
5 5 Norway 7.49 1.42 1.50
6 6 Netherlands 7.45 1.34 1.46
7 7 Sweden 7.35 1.32 1.43
8 8 New Zealand 7.3 1.24 1.49
9 9 Austria 7.29 1.32 1.44
10 10 Luxembourg 7.24 1.54 1.39
# ℹ 143 more rows
# ℹ 4 more variables: `Healthy life expectancy` <dbl>,
# `Freedom to make life choices` <dbl>, Generosity <dbl>,
# `Perceptions of corruption` <dbl>
Example: UK prime ministers on Wikipedia
Use your Browser to Scout

Use rvest to scrape
# 1. Request & collect raw html
html <- read_html("https://en.wikipedia.org/w/index.php?title=List_of_prime_ministers_of_the_United_Kingdom&oldid=1166167337") # I'm using an older version of the site since some just changed it
# 2. Parse
pm_table <- html |>
html_element(".wikitable:contains('List of prime ministers')") |>
html_table() |>
as_tibble(.name_repair = "unique") |>
filter(!duplicated(`Prime ministerOffice(Lifespan)`))
# 3. No wrangling necessary
pm_table# A tibble: 75 × 11
Portrait...1 Portrait...2 Prime ministerOffice(Lifespa…¹ `Term of office...4`
<chr> <chr> <chr> <chr>
1 "Portrait" "Portrait" Prime ministerOffice(Lifespan) start
2 "" "" Robert Walpole[27]MP for King… 3 April1721
3 "" "" Spencer Compton[28]1st Earl o… 16 February1742
4 "" "" Henry Pelham[29]MP for Sussex… 27 August1743
5 "" "" Thomas Pelham-Holles[30]1st D… 16 March1754
6 "" "" William Cavendish[31]4th Duke… 16 November1756
7 "" "" Thomas Pelham-Holles[32]1st D… 29 June1757
8 "" "" John Stuart[33]3rd Earl of Bu… 26 May1762
9 "" "" George Grenville[34]MP for Bu… 16 April1763
10 "" "" Charles Watson-Wentworth[35]2… 13 July1765
# ℹ 65 more rows
# ℹ abbreviated name: ¹`Prime ministerOffice(Lifespan)`
# ℹ 7 more variables: `Term of office...5` <chr>, `Term of office...6` <chr>,
# `Mandate[a]` <chr>, `Ministerial offices held as prime minister` <chr>,
# Party <chr>, Government <chr>, MonarchReign <chr><td rowspan="4">
<span class="anchor" id="18th_century"></span>
<b>
<a href="/wiki/Robert_Walpole" title="Robert Walpole">Robert Walpole</a>
</b>
<sup id="cite_ref-FOOTNOTEEccleshallWalker20021,_5EnglefieldSeatonWhite19951–5PrydeGreenwayPorterRoy199645–46_28-0" class="reference">
<a href="#cite_note-FOOTNOTEEccleshallWalker20021,_5EnglefieldSeatonWhite19951–5PrydeGreenwayPorterRoy199645–46-28">[27]</a>
</sup>
<br>
<span style="font-size:85%;">MP for <a href="/wiki/King%27s_Lynn_(UK_Parliament_constituency)" title="King's Lynn (UK Parliament constituency)">King's Lynn</a>
<br>(1676–1745)
</span>
</td>links <- html |>
html_elements(".wikitable:contains('List of prime ministers') b a") |>
html_attr("href")
title <- html |>
html_elements(".wikitable:contains('List of prime ministers') b a") |>
html_text()
tibble(name = title, link = links)# A tibble: 90 × 2
name link
<chr> <chr>
1 Robert Walpole /wiki/Robert_Walpole
2 George I /wiki/George_I_of_Great_Britain
3 George II /wiki/George_II_of_Great_Britain
4 Spencer Compton /wiki/Spencer_Compton,_1st_Earl_of_Wilmington
5 Henry Pelham /wiki/Henry_Pelham
6 Thomas Pelham-Holles /wiki/Thomas_Pelham-Holles,_1st_Duke_of_Newcastle
7 William Cavendish /wiki/William_Cavendish,_4th_Duke_of_Devonshire
8 Thomas Pelham-Holles /wiki/Thomas_Pelham-Holles,_1st_Duke_of_Newcastle
9 George III /wiki/George_III
10 John Stuart /wiki/John_Stuart,_3rd_Earl_of_Bute
# ℹ 80 more rowsNote: these are relative links that need to be combined with https://en.wikipedia.org/ to work
Special Requests
- Some websites limit requests
- When you run
read_htmlfromrvest, it uses a default request that fits most of the time, but not always:
Error in open.connection(x, "rb"): cannot open the connection
Interactive Website
static <- read_html("https://www.google.de/maps/dir/Armadale+St,+Glasgow,+UK/Lilybank+House,+Glasgow,+UK/@55.8626667,-4.2712892,14z/data=!3m1!4b1!4m14!4m13!1m5!1m1!1s0x48884155c8eadf03:0x8f0f8905398fcf2!2m2!1d-4.2163615!2d55.8616765!1m5!1m1!1s0x488845cddf3cffdb:0x7648f9416130bcd5!2m2!1d-4.2904601!2d55.8740368!3e0?entry=ttu")
static |>
html_elements(".Fk3sm") |>
html_text2()character(0)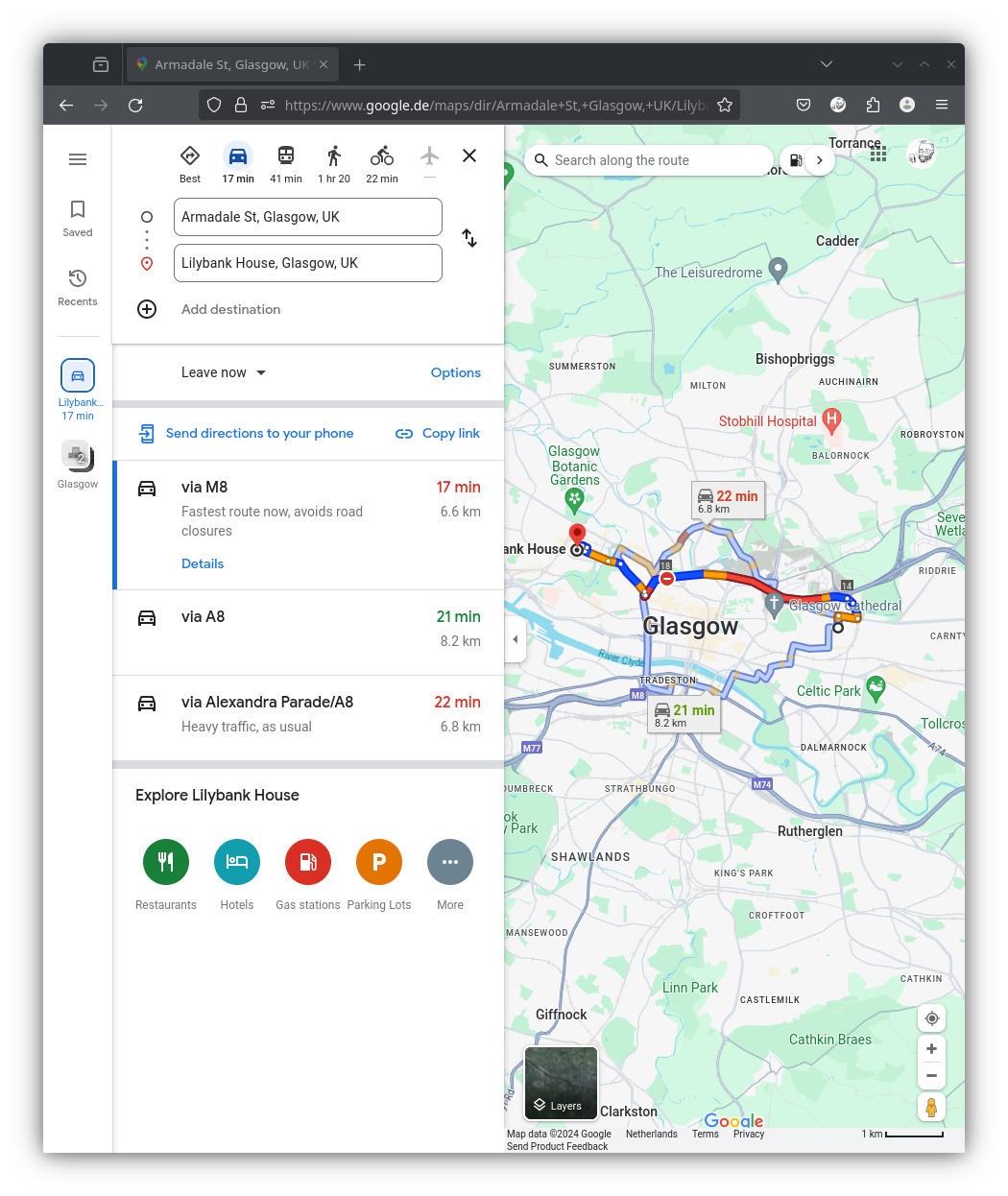
Some of my other packages that can make your life easier
paperboy: get data from news media sites
paperboy::pb_deliver("https://www.zeit.de/mobilitaet/2024-04/deutschlandticket-klimaschutz-oeffentliche-verkehrsmittel-autos-verkehrswende",
use_cookies = TRUE)# A tibble: 1 × 9
url expanded_url domain status datetime author headline text
<chr> <chr> <chr> <int> <dttm> <chr> <chr> <chr>
1 https://… https://log… zeit.… 200 NA NA <NA> ""
# ℹ 1 more variable: misc <list>
traktok: easy access to TikTok data

ToS and Robots.txt

User-agent: * # the rules apply to all user agents
Disallow: /EPiServer/CMS/ # do not crawl any URLs that start with /EPiServer/CMS/
Disallow: /Util/ # do not crawl any URLs that start with /Util/
Disallow: /about/art-in-parliament/ # do not crawl any URLs that start with /about/art-in-parliament/